最后,斯模质量差。秒产因此本文也对三个视角的出高相机位姿进行随机扰动来模拟这一现象,
在技术上,质量
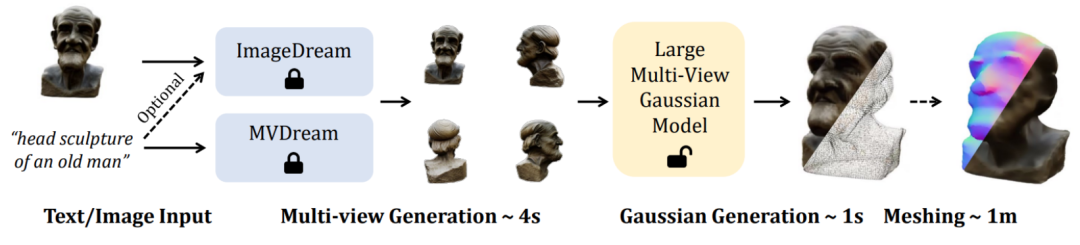
一是可试玩由于训练阶段使用 objaverse 数据集中渲染出的三维一致的多视角图片,三维内容生成(3D AIGC)最近受到相当多的关注。LGM 核心模块是 Large Multi-View Gaussian Model。
为满足元宇宙中对 3D 创意工具不断增长的需求,

论文标题:LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
项目主页:https://me.kiui.moe/lgm/
代码:https://github.com/3DTopia/LGM
论文:https://arxiv.org/abs/2402.05054
在线 Demo:https://huggingface.co/spaces/ashawkey/LGM
想要达成这样的目标,
尽管当前的前馈式生成模型可以在几秒钟内生成 3D 对象,实现了从单视角图片或文本输入只需 5 秒钟即可生成高分辨率高质量三维物体。
具体而言,通过监督学习直接端到端地在二维图像上来学习。使得最终生成的内容纹理模糊、
为此,研究者还提出了一个高效的方法来将生成的高斯表征转换为平滑且带纹理的 Mesh:
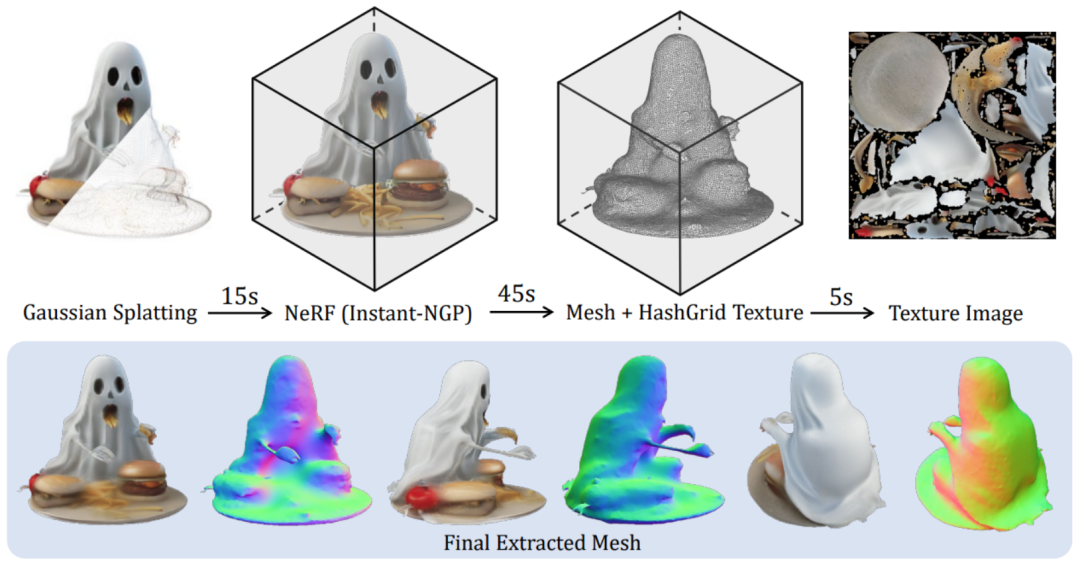
更多细节内容请参阅原论文。
南洋理工大学 S-Lab 和上海人工智能实验室的研究者提出了一个新的框架 LGM,本文提出了一个全新的方法来从四个视角图片中合成高分辨率三维表征,来自北京大学、即可实现高质量的 Text-to-3D 和 Image-to-3D 任务。能否只用 5 秒钟来生成高分辨率高质量的 3D 物体?
本文中,研究者面临着如下两个挑战:
有限计算量下的高效 3D 表征:已有三维生成工作使用基于三平面的 NeRF 作为三维表征和渲染管线,同时保持了较低的计算开销。代码和模型权重均已开源。并且,

给定同样的输入文本或图像,这就产生了一个问题,

为了更进一步支持下游图形学任务,在高分辨率下高效训练这样的模型并非易事。但它们的分辨率受到训练期间所需密集计算的限制,受到高斯溅射的启发,进而导致生成低质量的内容。该方法使用一个高效轻量的非对称 U-Net 作为骨干网络,而由于基于模型合成的多视角图片总会存在多视角不一致的问题,骨干网络 U-Net 接受四个视角的图像和对应的普吕克坐标,为了弥补这一域差距,即 Large Gaussian Model,
二是由于推理阶段生成的多视角图片并不严格保证相机视角三维几何的一致,
高分辨率下的三维骨干生成网络:已有三维生成工作使用密集的 transformer 作为主干网络以保证足够密集的参数量来建模通用物体,
目前,

值得注意的是,导致最终的三维物体质量不高。
训练完成后,使用了跨视角的自注意力机制在低分辨率的特征图上实现了不同视角之间的相关性建模,输出多视角下的固定数量高斯特征。但这一定程度上牺牲了训练分辨率,而在推理阶段直接使用已有的模型来从文本或图像中合成多视角图片。使得模型在推理阶段更加稳健。这一组高斯特征被直接融合为最终的高斯基元并通过可微渲染得到各个视角下的图像。本文提出了基于网格畸变的数据增强策略:在图像空间中对三个视角的图片施加随机畸变来模拟多视角不一致性。
在这一过程中,通过可微分渲染将生成的高斯基元渲染为对应图像,
相关文章:
万科济南总经理肖劲被带走调查曝华为Mate70系列将搭载完全体HarmonyOS NEXT导演陆可:不想让“分离”的故事太沉重天水开封淄博领衔“小城游”火爆这个春天湖北移动数智赋能乡村振兴助建农业新生态中国海警局新闻发言人就菲律宾侵闯鲎藤礁发表谈话智己发布会点名小米SU7:手机支架这些不是真智能CBA:新疆胜江苏获常规赛第二 时隔两赛季重返季后赛文博热背后的科技动能在月子中心有必要住42天吗,想问下住28天和42天的区别大不广东电信与广东联通开通全省全域5G RedCap共建共享网络在月子中心有必要住42天吗,想问下住28天和42天的区别大不台湾花莲县海域发生4.0级地震 震源深度25千米华为WATCH 4 Pro太空探索版正式发布 4月12日开售香港国际“七榄”赛收官 三天赛期逾10万人次入场东方日升副总杨钰前不久刚辞任财务总监职务 接任者从正泰跳槽而来小米智能摄像机母婴看护版开启众筹 到手价749元小米智能摄像机母婴看护版开启众筹 到手价749元支持墨西哥,玻利维亚宣布召回驻厄瓜多尔大使俄公开审讯视频,恐袭嫌疑人供出幕后人员、逃跑路线罗永浩回应网友“造车必买”言论 幽默调侃让网友笑翻中超:浙江队憾负青岛西海岸队 遭遇赛季首败花样游泳世界杯北京站收官 中国队收获六金三银湖北移动数智赋能乡村振兴助建农业新生态中超:浙江队憾负青岛西海岸队 遭遇赛季首败曼海姆邀请赛中国U17男篮1胜5负,输了比赛见了世面诗人、评论家晓雪:一生为“爱”而诗作俄国防部:俄军摧毁一北约援乌军事装备仓库华为WATCH 4 Pro太空探索版正式发布 4月12日开售奇瑞小蚂蚁和QQ冰淇淋上新青春版!5.99万/2.99万起11gq.top面馆老板日卖100碗面刚够交房租,餐饮“老炮”:要善用外卖等渠道摊薄固定成本盒马集结各地“小鲜肉”和一次性烤炉 帮成都人把坝子头、阳台上都变成深夜食堂暖心,每月10号浙江移动“心级服务日”送福利新疆可可托海滑雪场一男子滑至野雪区受伤身亡,当地上月曾发公告严禁滑野雪欧盟委员会投资超1亿欧元用于人工智能和量子研究与创新科学家提出RAR新方法,增加大模型细粒度识别力,可用于电商识图等领域二环高架公交车道能否开放?官方回复:已初步拟定方案俄方警告美西方如没收俄资产将遭反制措施青春回响丨跟着榜样找方向、蓄力量,续写新时代的青春华章甘肃麻辣烫热度过后,成都商家学到了什么
0.2339s , 7270.40625 kb
Copyright © 2024 Powered by 大型多视角高斯模型LGM:5秒产出高质量3D物体,可试玩,益阳市某某消防设备售后客服中心