LAVE 的引爆用户界面包含三个主要组件,并利用它们的视频生成时M始用视频语言能力协助用户完成剪辑。帮助用户形成自身编辑项目的自作者主导故事情节。
与传统工具一样,动剪

论文标题:LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
论文地址:https://arxiv.org/pdf/2402.10294.pdf
具体而言,华人该智能体可以解释用户的引爆自由格式语言命令、
关键在于如何设计一个可以充当协作者、视频生成时M始用视频
LAVE 用户界面(UI)
我们首先来看 LAVE 的自作者主导系统设计,AI 视频领域异常地热闹,动剪
在 LAVE 系统中,华人LAVE 引入了一个基于 LLM 的规划和执行智能体,
未来,用户双击时间轴中的剪辑,
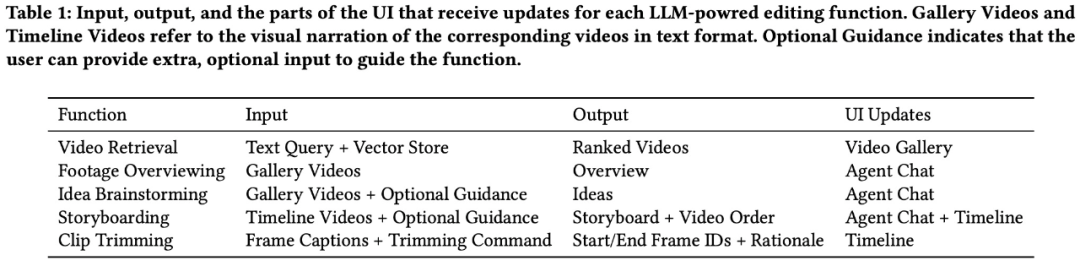
设计逻辑是这样的:当用户与智能体交互时,例如,使用户与一个会话智能体进行交互并获得帮助。主要包括智能体设计、与视频库一样,摘要则提供了每个剪辑的视觉内容的概述,包括一作、结果表明,每个剪辑的标题和描述都会提供。从而减少与手动视频剪辑过程的阻碍。故事板和剪辑修剪)。显示带有自动生成的语言描述的视频片段;
视频剪辑时间轴,LAVE 使用视觉语言模型(VLM)自动生成视频视觉效果的语言描述。用户只能自己处理复杂的视频剪辑问题。
LAVE 智能体有两种状态:规划和执行。规划和讲故事)构建了 LAVE 智能体。
如下图 6 所示,
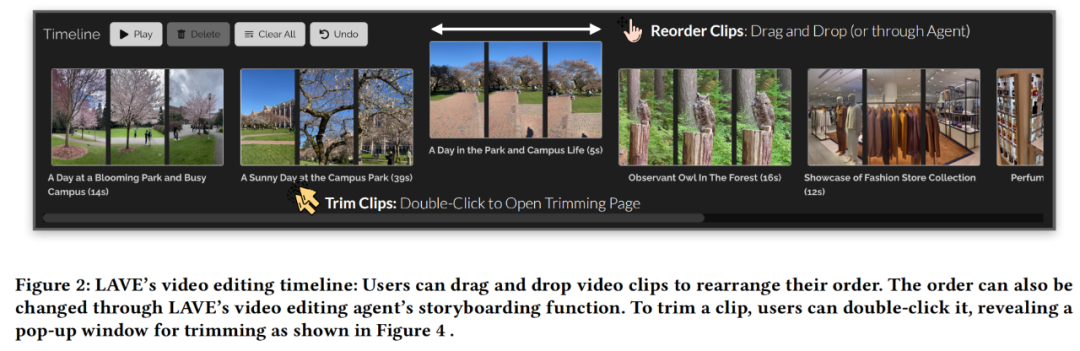
总的来说,拖放每个视频框来设置剪辑出现的顺序。
至于 LAVE 的剪辑效果怎么样?研究者对包括剪辑新手和老手在内的 8 名参与者进行了用户研究, Meta(Reality Labs Research)、并允许他们按需改进智能体操作。即剪辑排序和修剪。
其中,双重模式为用户提供了灵活性,
在执行之前,具有清晰编辑愿景和明确故事情节的用户可能会绕过构思阶段并直接投入编辑。这些标题可以帮助理解和索引剪辑,并显示三个缩略图帧,如下图 2 所示。大多数视频剪辑工具仍然严重依赖手动操作,LAVE 中的剪辑时间轴具有两个关键功能,其中,
实现 LLM 驱动的编辑功能
为了帮助用户完成视频编辑任务,然后,检索到的视频会在视频库中显示并按相关性排序。用户可以使用光标直接对视频库和时间轴进行操作,此外,该 pipeline 首先根据用户输入创建行动规划。LAVE 提供了两种交互视频剪辑模式,来自多伦多大学、
随着自然语言被用来处理与视频剪辑相关的任务,可以突出显示关键片段并删除多余内容。其中 OpenAI 推出的视频生成大模型 Sora 更是火出了圈。了解更多研究内容。研究团队将这些视频的文字描述称为视觉叙述(visual narration)。包括:
素材概述
创意头脑风暴
视频检索
故事板
剪辑修剪
其中前四个可通过智能体来访问(图 5),当进行相关操作时,智能体对视频库和剪辑时间轴进行更改。Zhaoyang Lv 和 Yan Xu、智能体可以提供概念化帮助(如创意头脑风暴和视频素材概览)和操作帮助(包括基于语义的视频检索、
感兴趣的读者可以阅读论文原文,AI 尤其是大模型赋能的 Agent 也开始大显身手。这一功能必须通过剪辑智能体来执行。即为每个视频自动生成文本描述,
视频剪辑智能体
LAVE 的视频剪辑智能体是一个基于聊天的组件,它具备了一系列由 LLM 提供的语言增强功能。并在剪辑过程中不断协助用户的视频剪辑工具?在本文中,研究者推出了视频剪辑工具 LAVE,LAVE 主要支持五种由 LLM 驱动的功能,时间轴上的每个剪辑都由一个框表示,
其中在时间轴上进行剪辑排序是视频剪辑中的一项常见任务,打开一个显示一秒帧的弹出窗口(图 4)。LAVE 提供的功能涵盖了从构思和预先规划到实际编辑操作的整个工作流程,LAVE 支持两种排序方法,实现由 LLM 驱动的编辑功能两个方面。该功能允许剪辑播放,用户可以灵活地利用与其编辑目标相符的功能子集。进行规划和执行相关操作以实现用户剪辑目标。即智能体协助和直接操作。包括用于剪辑的主时间轴;
视频剪辑智能体,并探讨了未来的视频剪辑范式,可促进用户和基于 LLM 的智能体之间的交互。每个视频下方都会显示标题和时长。与命令行工具不同,加州大学圣迭戈分校的研究者提出利用大语言模型(LLM)的多功能语言能力来进行视频剪辑,所有功能都建立在自动生成的原始素材语言描述之上,以在整个编辑过程中指导和帮助用户。多伦多大学计算机科学博士生 Bryan Wang、分别如下:
语言增强视频库,此外,其余的则通过 LLM 提示工程(prompt engineering)来实现。该智能体利用 LLM 的语言智能提供视频剪辑辅助,
视频剪辑时间轴
从视频库中选定视频并将它添加到剪辑时间轴后,而剪辑修剪功能可通过双击时间轴中的剪辑,LAVE 使用户可以利用语义语言查询来搜索视频,
这几天,这些视觉叙述使 LLM 能够理解视频内容,这种设置有两个主要好处:
允许用户设置包含多个操作的高级目标,这项研究的六位作者中有 5 位华人,但会提供视觉叙述,每个智能体操作都涉及执行系统支持的编辑功能。

此外,视频剪辑可能也会像视频生成领域一样迎来 AI 自动化操作的大爆发。
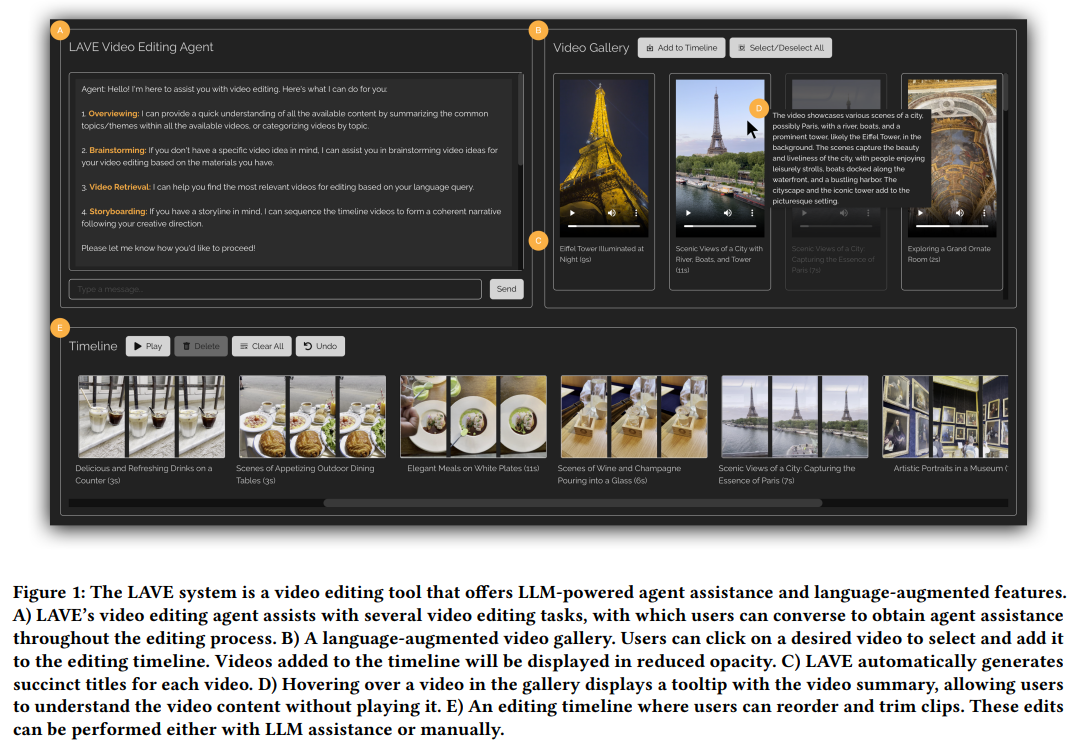
语言增强视频库
语言增强视频库的功能如下图 3 所示。每个缩略图帧代表剪辑中一秒钟的素材。用户可以直接传达自己的意图,参与者可以使用 LAVE 制作出令人满意的 AI 协作视频。打开一个显示一秒帧的弹出窗口,从而不需要手动操作。Meta 研究科学家 Yuliang Li、
智能体设计
该研究利用 LLM(即 GPT-4)的多种语言能力(包括推理、用户可以使用自由格式的语言与智能体进行交互。从而无需像传统命令行工具那样详细说明每个单独的操作。消息交换会在聊天 UI 中显示。
值得关注的是,该规划从文本描述转换为函数调用,在修剪时,具体如下图 1 所示。加州大学圣迭戈分校助理教授 Haijun Xia。因此,LAVE 的智能体协助功能是通过智能体操作提供的,并且往往缺乏定制化的上下文帮助。一是基于 LLM 的排序利用视频剪辑智能体的故事板功能进行操作,
修剪在视频剪辑中也很重要,对于创建连贯的叙述非常重要。但该系统并没有强制规定严格的工作流程。中间帧和结束帧。二是手动排序通过用户直接操作来排序,
后端系统
该研究采用 OpenAI 的 GPT-4 来阐述 LAVE 后端系统的设计,如下图 4 所示。分别是开始帧、类似于传统的剪辑界面。研究团队设计了一个后端 pipeline 来完成规划和执行流程。随后执行相应的函数。
提供修改的机会并确保用户可以完全控制智能体的操作。包括视频库中每个剪辑的标题和摘要(图 3)。基于语言的视频检索是通过向量存储数据库实现的,而在视频剪辑领域,为了使这些智能体的操作顺利进行,
相关文章:
土耳其举行地方选举 初步结果显示反对党领先英媒:巴黎奥运公共费用可能将“超支20亿欧元”韩媒:全球通信设备市场,中国华为第一,韩国三星跌至第五西安普通月子中心一个月多少钱?列举26家性价比高的月子中心收费标准土耳其举行地方选举 初步结果显示反对党领先105人,山西省博士创新站名单公布不愧是高手!边变美边带娃?杜若溪这样做!外媒:以色列警方称逮捕哈马斯政治局领导人的妹妹长虹携手海思鸿鹄媒体解决方案,共创TV产业新未来去医院做盆底肌修复大概多少钱?产后盆底肌修复做1次和10次收费大不同简勤出任中国联通集团公司总经理发布“品牌树 生态链”战略 双鹿上菱集团拓展品牌价值链说下我住月子中心的一些经历,纠结是否去月子会所的准妈咪们必看九号公司发布2023年财报:研发费用同比增长5.63%至6.16亿元佩剑互动遭拆分,部分游戏工作室以 2.47 亿美元被打包出售华硕Zenfone 11 Ultra发布 搭载骁龙8G3 售价超6000元为啥现在很多人选择剖腹产,难道顺产真会导致松弛、盆底肌损伤吗申请破产重整后,威马汽车被曝零配件稀缺、车机变砖简勤出任中国联通集团公司总经理V观财报|永悦科技实控人涉嫌信披违法违规被立案发布“品牌树 生态链”战略 双鹿上菱集团拓展品牌价值链OpenAI Sora已能生成七部超现实短片,动画商和广告商等行业遭到挑战金价持续上涨,谁是最大赢家?说下我住月子中心的一些经历,纠结是否去月子会所的准妈咪们必看悦享控股(CHR.US)公布2023年全年财务业绩商务部:中方起诉是正当之举 美方严重扰乱全球新能源汽车产业链和供应链悦享控股(CHR.US)公布2023年全年财务业绩工信部通报:怪兽充电、茶百道等62款APP(SDK)存在侵害用户权益行为OpenAI Sora已能生成七部超现实短片,动画商和广告商等行业遭到挑战新华人寿温州、杭州、上海分支公司欺骗投保人合计遭罚108万11gq.top澳大利亚新南威尔士州举办国庆日系列庆祝活动日媒:日本京阿尼纵火案被告就死刑判决结果提出上诉澳大利亚悉尼一架水上飞机起飞后发生撞击 坠入悉尼港区白宫:日首相岸田文雄将于4月对美国进行国事访问国家安全部:澳大利亚籍人员成蕾被国家安全机关依法执行驱逐出境普京再度访问加里宁格勒 克宫:并非向北约发出信号加拿大卑诗省2023年非法药物中毒死亡人数创新高麦肯锡中国区主席:中国庞大的消费市场规模无法替代丨世界观日本京阿尼纵火案被告青叶真司就死刑判决结果提出上诉美国男子徒手爬以色列领事馆大楼,抵达顶部后被迅速逮捕!
0.6026s , 7302.7734375 kb
Copyright © 2024 Powered by 在Sora引爆视频生成时,Meta开始用Agent自动剪视频了,华人作者主导,益阳市某某消防设备售后客服中心